
After several years as a research analyst in the nonprofit sector, I wanted to do more than just report on trends — I wanted to build the tools that drive them. I made a leap into data science to close the gap between analysis and real-world impact. I developed the technical foundation to support and scale my work through a Master’s degree in computer science.
As I learned, I built a portfolio that reflects both my social science background and my growth as a technical contributor. I focused on statistical modeling, data mining, and machine learning while building interactive tools with Python, SQL, and Power BI. Having completed my degree with distinction, I am seeking full-time opportunities to apply those skills. This site highlights projects and ideas that have shaped my journey so far.
Modeling Socioeconomic Ascent in Connecticut Census Tracts
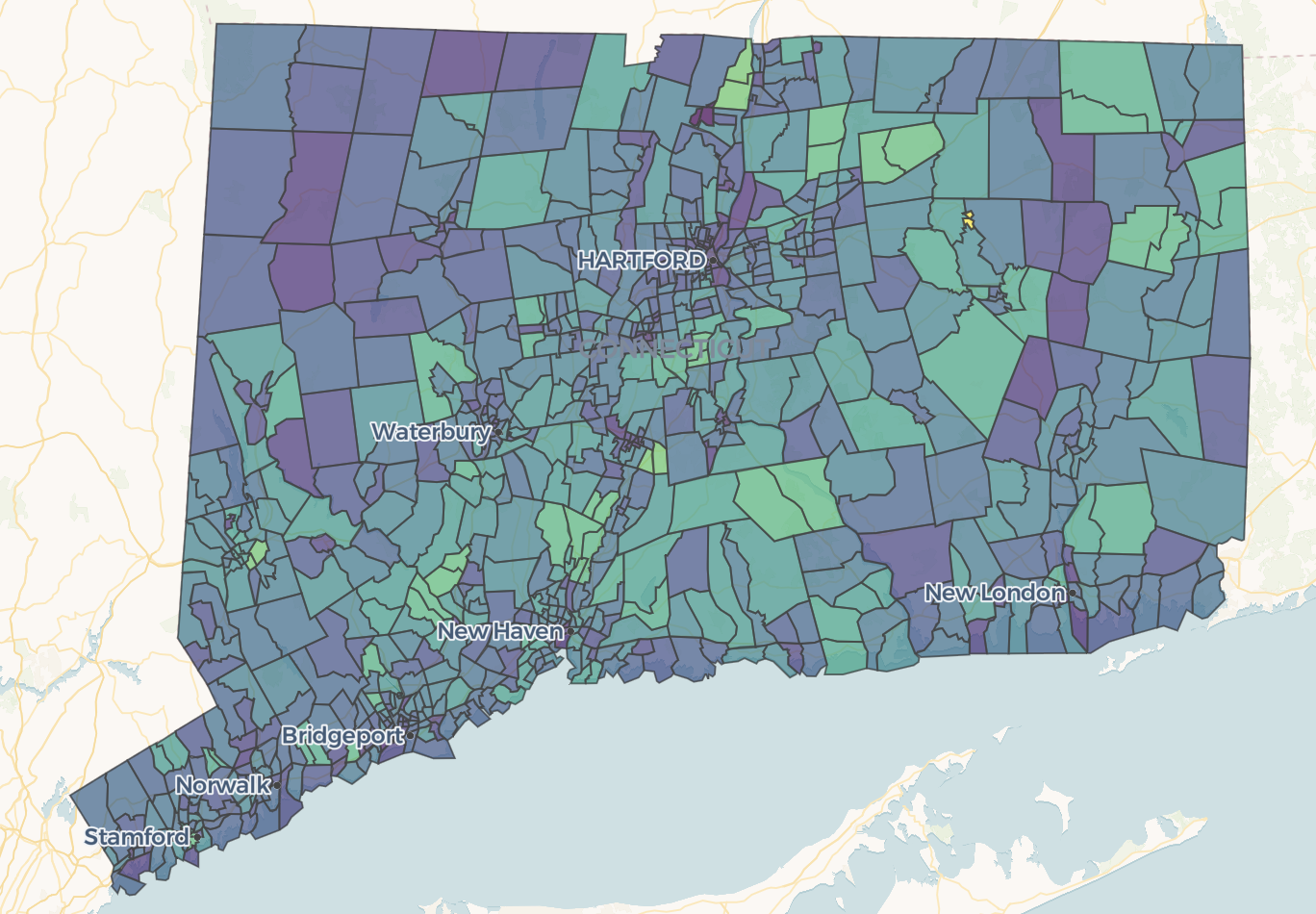
Developed a machine learning framework to predict socioeconomic development across Connecticut’s census tracts, comparing statistical methods like OLS, random forest, and gradient boosting. The project involved preprocessing socioeconomic indicators, training models, and evaluating their performance to identify the most accurate approach. By analyzing these predictive techniques, the research supports data-driven decision-making in urban planning, investment, and resource allocation for Connecticut’s towns and regions.
Technologies: Python
PostgreSQL
Skills: scikit-learn pandas geopandas K-Means Clustering Random Forest APIs
Using Principal Component Analysis to Produce a Composite Variable for Socioeconomic Analysis
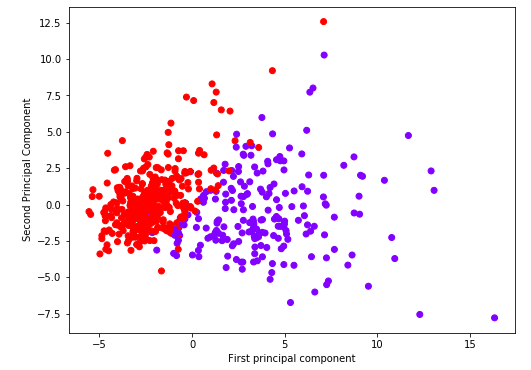
I transformed raw socioeconomic data from the U.S. Census into an elegant composite metric using PCA. By extracting maximum variance through eigenvalue decomposition, we bypass arbitrary weighting and derive a statistically robust SES metric. Validation such as correlation and variance analysis helps strengthens the reliability of our approach and aligns with best practices in quantitative social science.
Technologies: ![]() Google BigQuery
Google BigQuery
Skills: Python PCA eigenvectors scikit-learn Dimensionality Reduction
U.S. State Exports Dashboard in Power BI
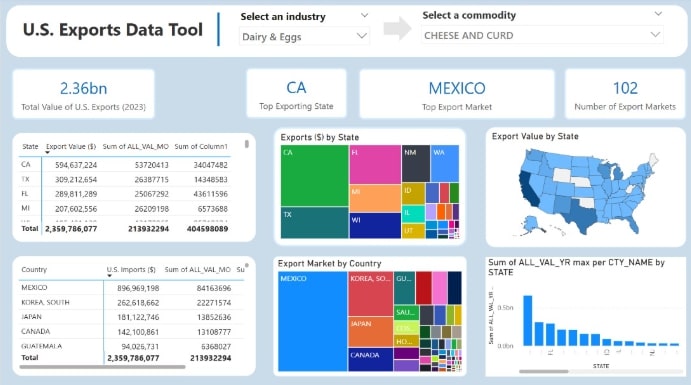
Built a dynamic global trade dashboard in Power BI using DAX expressions and Power Query for advanced data modeling and visualization. Integrated multiple data sources to create interactive reports highlighting trade patterns and key metrics across regions. Populated SQL Server database with 2.1M-row master table across 100 tables with dynamic SQL queries.
Technologies: ![]() Power BI
Power BI
 SQL Server
Azure
SQL Server
Azure
Skills: Data Modeling DAX Dynamic SQL Star Schema
Predictive Modeling of Credit Default Using Advanced Data Mining Techniques
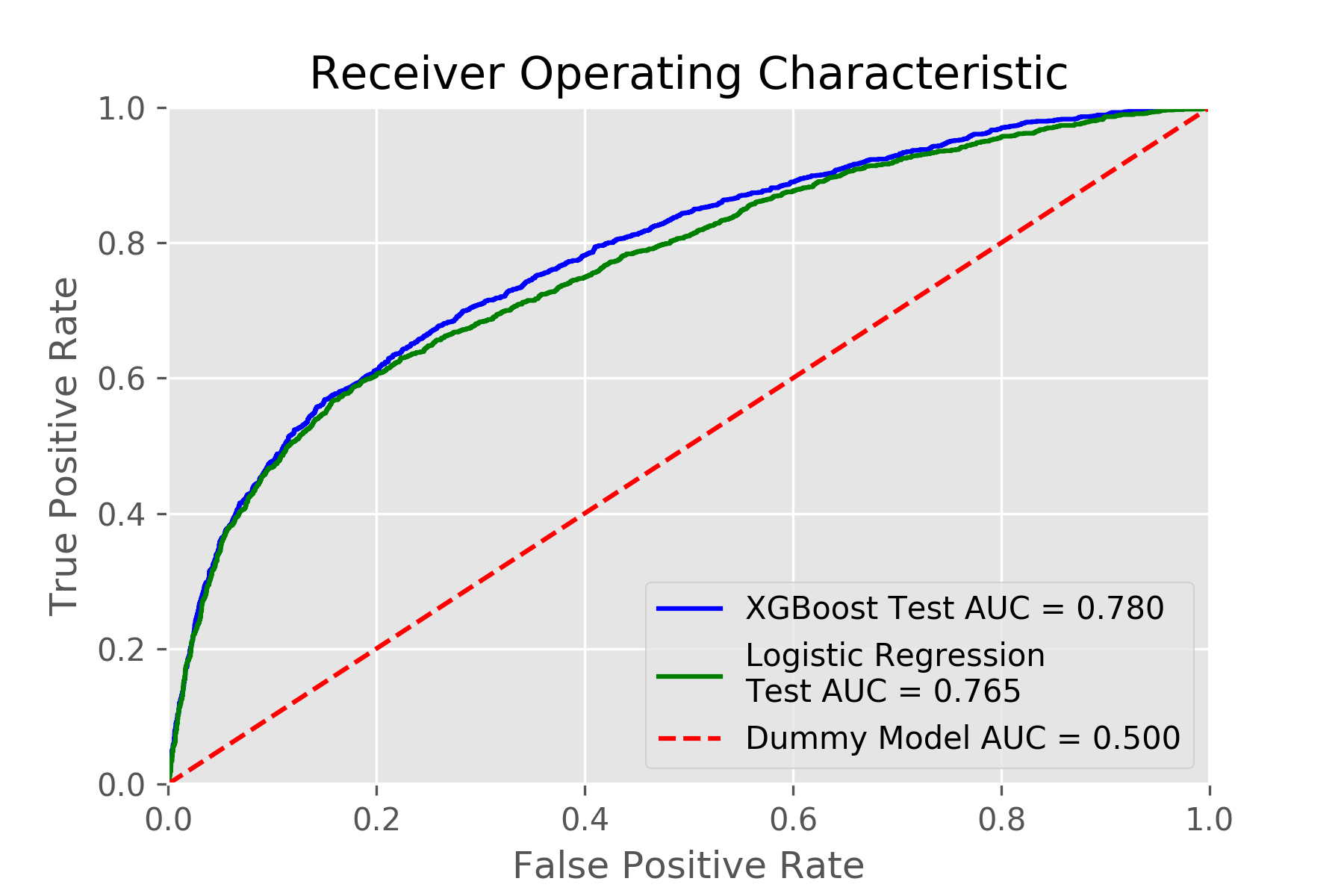
This project implements a robust machine learning framework for credit default prediction, leveraging the UCL German Credit Dataset and benchmarking performance against the methodologies proposed in I-Cheng Yeh & Che-hui Lien’s 2009 paper ("The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients"). We extend their work by incorporating modern XGBoost optimization and conducting a rigorous comparative analysis of model performance.
Technologies: ![]() Apache Spark
Apache Spark
![]() VBA
VBA
![]() Excel
Excel
Skills: Excel macros Process automation Predictive Modeling Analytics
-
Creating the Neural Network Menu/ March 24, 2025
Reviewing how I created the interactive navigation menu you see on the left sidebar of this site. I learned about DOM, even listeners, and basic CSS/JavaScript tradeoffs.
-
Modeling Socioeconomic Ascent in Connecticut Census Tracts/ March 13, 2025
Using public Census data, I applied data mining algorithms to model the socioeconomic correlations of economic growth on the 884 official Census tracts of Connecticut to generate 5-year forecasts for the year 2028.
-
Using Principal Component Analysis to Produce a Composite Variable for Socioeconomic Analysis/ February 19, 2025
As part of my M.S. thesis, I used PCA to compress 3 variables into a single variable for use as my predictor variable. I discuss tradeoffs of PCA in the context of my specific problem case.
-
A Simple Notification System for Amazon Book Wishlist/ January 8, 2025
A Python-based notification system that monitors changes in the price or availability of books on your Amazon wishlist. Users receive email alerts when key changes occur, helping them stay updated on their desired books.
-
Quick Deployment of a Simple Machine Learning Model with Streamlit/ December 27, 2024
How to deploy a simple machine learning model using Streamlit, turning a trained model into an interactive web app.
-
Generalizing Regression: t-tests and OLS/ December 23, 2024
Exploring the idea that t-tests for comparing group means are mathematically equivalent to performing OLS regression with a binary predictor, highlighting the flexibility and power of regression analysis.
</span>